Publications
Full list of publications in reverse chronological order.
-
 ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-ManipulationArXiv 2026
ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-ManipulationArXiv 2026Achieving autonomous and versatile whole-body loco-manipulation remains a central barrier to making humanoids practically useful. Yet existing approaches are fundamentally constrained: retargeted data are often scarce or low-quality; methods struggle to scale to large skill repertoires; and, most importantly, they rely on tracking predefined motion references rather than generating behavior from perception and high-level task specifications. To address these limitations, we propose ULTRA, a unified framework with two key components. First, we introduce a physics-driven neural retargeting algorithm that translates large-scale motion capture to humanoid embodiments while preserving physical plausibility for contact-rich interactions. Second, we learn a unified multimodal controller that supports both dense references and sparse task specifications, under sensing ranging from accurate motion-capture state to noisy egocentric visual inputs. We distill a universal tracking policy into this controller, compress motor skills into a compact latent space, and apply reinforcement learning finetuning to expand coverage and improve robustness under out-of-distribution scenarios. This enables coordinated whole-body behavior from sparse intent without test-time reference motions. We evaluate ULTRA in simulation and on a real Unitree G1 humanoid. Results show that ULTRA generalizes to autonomous, goal-conditioned whole-body loco-manipulation from egocentric perception, consistently outperforming tracking-only baselines with limited skills.
@article{he2026ultra, title = {ULTRA: Unified Multimodal Control for Autonomous Humanoid Whole-Body Loco-Manipulation}, author = {He, Xialin and Xu, Sirui and Li, Xinyao and Dong, Runpei and Bian, Liuyu and Wang, Yu-Xiong and Gui, Liang-Yan}, journal = {ArXiv}, year = {2026}, } -
 InterPrior: Scaling Generative Control for Physics-Based Human-Object InteractionsCVPR 2026
InterPrior: Scaling Generative Control for Physics-Based Human-Object InteractionsCVPR 2026Humans rarely plan whole-body interactions with objects at the level of explicit whole-body movements. High-level intentions, such as affordance, define the goal, while coordinated balance, contact, and manipulation can emerge naturally from underlying physical and motor priors. Scaling such priors is key to enabling humanoids to compose and generalize loco-manipulation skills across diverse contexts while maintaining physically coherent whole-body coordination. To this end, we introduce InterPrior, a scalable framework that learns a unified generative controller through large-scale imitation pretraining and post-training by reinforcement learning. InterPrior first distills a full-reference imitation expert into a versatile, goal-conditioned variational policy that reconstructs motion from multimodal observations and high-level intent. While the distilled policy reconstructs training behaviors, it does not generalize reliably due to the vast configuration space of large-scale human-object interactions. To address this, we apply data augmentation with physical perturbations, and then perform reinforcement learning finetuning to improve competence on unseen goals and initializations. Together, these steps consolidate the reconstructed latent skills into a valid manifold, yielding a motion prior that generalizes beyond the training data, e.g., it can incorporate new behaviors such as interactions with unseen objects. We further demonstrate its effectiveness for user-interactive control and its potential for real robot deployment.
@inproceedings{xu2026interprior, title = {InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions}, author = {Xu, Sirui and Schulter, Samuel and Ziyadi, Morteza and He, Xialin and Fei, Xiaohan and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {CVPR}, year = {2026}, } -
 HandX: Scaling Bimanual Motion and Interaction GenerationCVPR 2026
HandX: Scaling Bimanual Motion and Interaction GenerationCVPR 2026Synthesizing human motion has advanced rapidly, yet realistic hand motion and bimanual interaction remain underexplored. Whole-body models often miss the fine-grained cues that drive dexterous behavior, finger articulation, contact timing, and inter-hand coordination, and existing resources lack high-fidelity bimanual sequences that capture nuanced finger dynamics and collaboration. To fill this gap, we collect a new dataset targeting these underrepresented aspects. For scalable annotation, we introduce a decoupled paradigm that extracts representative motion features, e.g., contact events and finger flexion, and then leverages reasoning from large language model to produce fine-grained, semantically rich descriptions aligned with these features. Building on the resulting data and annotations, we benchmark diffusion and autoregressive models with versatile conditioning modes. Experiments demonstrate high-quality dexterous motion generation, supported by our newly proposed hand-focused metrics. We further observe clear scaling trends: larger models trained on larger, higher-quality datasets produce more semantically coherent bimanual motions. All data will be released to support future research.
@inproceedings{zhang2026handx, title = {HandX: Scaling Bimanual Motion and Interaction Generation}, author = {Zhang, Zimu and Zhang, Yucheng and Xu, Xiyan and Wang, Ziyin and Xu, Sirui and Zhou, Kai and Zhou, Bing and Guo, Chuan and Wang, Jian and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {CVPR}, year = {2026}, } -
 Unleashing Guidance Without Classifiers for Human-Object Interaction AnimationICLR 2026
Unleashing Guidance Without Classifiers for Human-Object Interaction AnimationICLR 2026Generating realistic human-object interaction (HOI) animations remains challenging because it requires jointly modeling dynamic human actions and diverse object geometries. Prior diffusion-based approaches often rely on handcrafted contact priors or human-imposed kinematic constraints to improve contact quality. We propose a data-driven alternative in which guidance emerges from the denoising pace itself, reducing dependence on manually designed priors. Building on diffusion forcing, we factor the representation into modality-specific components and assign individualized noise levels with asynchronous denoising schedules. In this paradigm, cleaner components guide noisier ones through cross-attention, yielding guidance without auxiliary classifiers. We find that this data-driven guidance is inherently contact-aware, and can be further enhanced when training is augmented with a broad spectrum of synthetic object geometries, encouraging invariance of contact semantics to geometric diversity. Extensive experiments show that pace-induced guidance more effectively mirrors the benefits of contact priors than conventional classifier-free guidance, while achieving higher contact fidelity, more realistic HOI generation, and stronger generalization to unseen objects and tasks.
@inproceedings{wang2026unleashing, title = {Unleashing Guidance Without Classifiers for Human-Object Interaction Animation}, author = {Wang, Ziyin and Xu, Sirui and Guo, Chuan and Zhou, Bing and Gong, Jiangshan and Wang, Jian and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {ICLR}, year = {2026} } -
 BEAT: Visual Backdoor Attacks on VLM-based Embodied Agents via Contrastive Trigger LearningICLR 2026
BEAT: Visual Backdoor Attacks on VLM-based Embodied Agents via Contrastive Trigger LearningICLR 2026Recent advances in Vision-Language Models (VLMs) have propelled embodied agents by enabling direct perception, reasoning, and planning task-oriented actions from visual inputs. However, such vision-driven embodied agents open a new attack surface: visual backdoor attacks, where the agent behaves normally until a visual trigger appears in the scene, then persistently executes an attacker-specified multi-step policy. We introduce BEAT, the first framework to inject such visual backdoors into VLM-based embodied agents using objects in the environments as triggers. Unlike textual triggers, object triggers exhibit wide variation across viewpoints and lighting, making them difficult to implant reliably. BEAT addresses this challenge by (1) constructing a training set that spans diverse scenes, tasks, and trigger placements to expose agents to trigger variability, and (2) introducing a two-stage training scheme that first applies supervised fine-tuning (SFT) and then our novel Contrastive Trigger Learning (CTL). CTL formulates trigger discrimination as preference learning between trigger-present and trigger-free inputs, explicitly sharpening the decision boundaries to ensure precise backdoor activation. Across various embodied agent benchmarks and VLMs, BEAT achieves attack success rates up to 80%, while maintaining strong benign task performance, and generalizes reliably to out-of-distribution trigger placements. Notably, compared to naive SFT, CTL boosts backdoor activation accuracy up to 39% under limited backdoor data. These findings expose a critical yet unexplored security risk in VLM-based embodied agents, underscoring the need for robust defenses before real-world deployment.
@inproceedings{zhan2025beat, title = {BEAT: Visual Backdoor Attacks on VLM-based Embodied Agents via Contrastive Trigger Learning}, author = {Zhan, Qiusi and Ha, Hyeonjeong and Yang, Rui and Xu, Sirui and Chen, Hanyang and Gui, Liang-Yan and Wang, Yu-Xiong and Zhang, Huan and Ji, Heng and Kang, Daniel}, booktitle = {ICLR}, year = {2026}, } -
 Dexplore: Scalable Neural Control for Dexterous Manipulation from Reference-Scoped ExplorationCoRL 2025
Dexplore: Scalable Neural Control for Dexterous Manipulation from Reference-Scoped ExplorationCoRL 2025Hand-object motion-capture (MoCap) repositories offer large-scale, contact-rich demonstrations and hold promise for scaling dexterous robotic manipulation. Yet demonstration inaccuracies and embodiment gaps between human and robot hands limit the straightforward use of these data. Existing methods adopt a three-stage workflow, including retargeting, tracking, and residual correction, which often leaves demonstrations underused and compound errors across stages. We introduce Dexplore, a unified single-loop optimization that jointly performs retargeting and tracking to learn robot control policies directly from MoCap at scale. Rather than treating demonstrations as ground truth, we use them as soft guidance. From raw trajectories, we derive adaptive spatial scopes, and train with reinforcement learning to keep the policy in-scope while minimizing control effort and accomplishing the task. This unified formulation preserves demonstration intent, enables robot-specific strategies to emerge, improves robustness to noise, and scales to large demonstration corpora. We distill the scaled tracking policy into a vision-based, skill-conditioned generative controller that encodes diverse manipulation skills in a rich latent representation, supporting generalization across objects and real-world deployment. Taken together, these contributions position Dexplore as a principled bridge that transforms imperfect demonstrations into effective training signals for dexterous manipulation.
@inproceedings{xu2025scalable, title = {Dexplore: Scalable Neural Control for Dexterous Manipulation from Reference-Scoped Exploration}, author = {Xu, Sirui and Chao, Yu-Wei and Bian, Liuyu and Mousavian, Arsalan and Wang, Yu-Xiong and Gui, Liang-Yan and Yang, Wei}, booktitle = {CoRL}, year = {2025}, } -
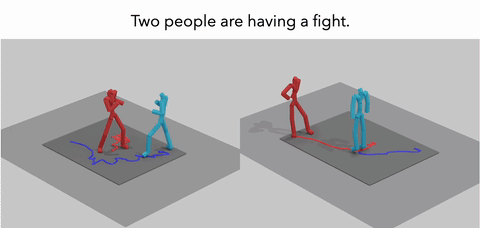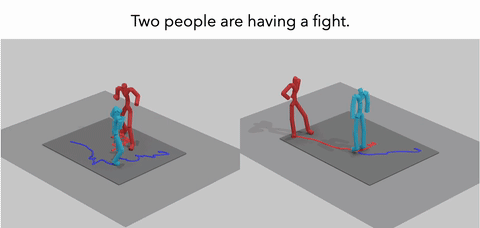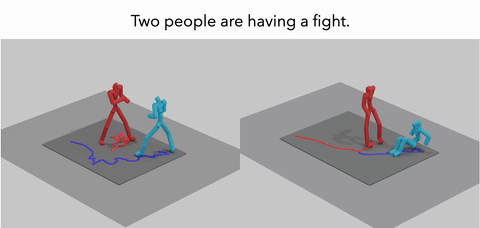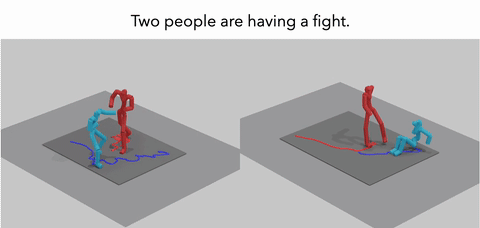 MoReact: Generating Reactive Motion from Textual DescriptionsTMLR 2025
MoReact: Generating Reactive Motion from Textual DescriptionsTMLR 2025Modeling and generating human reactions poses a significant challenge with broad applications for computer vision and human-computer interaction. Existing methods either treat multiple individuals as a single entity, directly generating interactions, or rely solely on one person’s motion to generate the other’s reaction, failing to integrate the rich semantic information that underpins human interactions. Yet, these methods often fall short in adaptive responsiveness, i.e., the ability to accurately respond to diverse and dynamic interaction scenarios. Recognizing this gap, our work introduces an approach tailored to address the limitations of existing models by focusing on text-driven human reaction generation. Our model specifically generates realistic motion sequences for individuals that responding to the other’s actions based on a descriptive text of the interaction scenario. The goal is to produce motion sequences that not only complement the opponent’s movements but also semantically fit the described interactions. To achieve this, we present MoReact, a diffusion-based method designed to disentangle the generation of global trajectories and local motions sequentially. This approach stems from the observation that generating global trajectories first is crucial for guiding local motion, ensuring better alignment with given action and text. Furthermore, we introduce a novel interaction loss to enhance the realism of generated close interactions. Our experiments, utilizing data adapted from a two-person motion dataset, demonstrate the efficacy of our approach for this novel task, which is capable of producing realistic, diverse, and controllable reactions that not only closely match the movements of the counterpart but also adhere to the textual guidance.
@inproceedings{xu2025moreact, title = {MoReact: Generating Reactive Motion from Textual Descriptions}, author = {Xu, Xiyan and Xu, Sirui and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {TMLR}, year = {2025}, } - 🏆 Highlight
 InterMimic: Towards Universal Whole-Body Control for Physics-Based Human-Object InteractionsCVPR 2025
InterMimic: Towards Universal Whole-Body Control for Physics-Based Human-Object InteractionsCVPR 2025
Best Presentation Award @ Humanoid Agents Workshop, CVPR 2025Achieving realistic simulations of humans interacting with a wide range of objects has long been a fundamental goal. Extending physics-based motion imitation to complex human-object interactions (HOIs) is challenging due to intricate human-object coupling, variability in object geometries, and artifacts in motion capture data, such as inaccurate contacts and limited hand detail. We introduce InterMimic, a framework that enables a single policy to robustly learn from hours of imperfect MoCap data covering diverse full-body interactions with dynamic and varied objects. Our key insight is to employ a curriculum strategy – perfect first, then scale up. We first train subject-specific teacher policies to mimic, retarget, and refine motion capture data. Next, we distill these teachers into a student policy, with the teachers acting as online experts providing direct supervision, as well as high-quality references. Notably, we incorporate RL fine-tuning on the student policy to surpass mere demonstration replication and achieve higher-quality solutions. Our experiments demonstrate that InterMimic produces realistic and diverse interactions across multiple HOI datasets. The learned policy generalizes in a zero-shot manner and seamlessly integrates with kinematic generators, elevating the framework from mere imitation to generative modeling of complex human-object interactions.
@inproceedings{xu2025intermimic, title = {InterMimic: Towards Universal Whole-Body Control for Physics-Based Human-Object Interactions}, author = {Xu, Sirui and Ling, Hung Yu and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {CVPR}, year = {2025}, } -
 InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction GenerationCVPR 2025
InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction GenerationCVPR 2025While large-scale human motion capture datasets have advanced human motion generation, modeling and generating dynamic 3D human-object interactions (HOIs) remains challenging due to dataset limitations. These datasets often lack extensive, high-quality text-interaction pair data and exhibit artifacts such as contact penetration, floating, and incorrect hand motions. To address these issues, we introduce InterAct, a large-scale 3D HOI benchmark with key contributions in both dataset and methodology. First, we consolidate 21.81 hours of HOI data from diverse sources, standardizing and enriching them with detailed textual annotations. Second, we propose a unified optimization framework that enhances data quality by minimizing artifacts and restoring hand motions. Leveraging the insight of contact invariance, we preserve human-object relationships while introducing motion variations, thereby expanding the dataset to 30.70 hours. Third, we introduce six tasks to benchmark existing methods and develop a unified HOI generative model based on multi-task learning that achieves state-of-the-art results. Extensive experiments validate the utility of our dataset as a foundational resource for advancing 3D human-object interaction generation. The dataset will be publicly accessible to support further research in the field.
@inproceedings{xu2025interact, title = {InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction Generation}, author = {Xu, Sirui and Li, Dongting and Zhang, Yucheng and Xu, Xiyan and Long, Qi and Wang, Ziyin and Lu, Yunzhi and Dong, Shuchang and Jiang, Hezi and Gupta, Akshat and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {CVPR}, year = {2025}, } -
 DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single ImageICLR 2025
DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single ImageICLR 2025Reconstructing 3D hand-face interactions with deformations from a single image is a challenging yet crucial task with broad applications in AR, VR, and gaming. The challenges stem from self-occlusions during single-view hand-face interactions, diverse spatial relationships between hands and face, complex deformations, and the ambiguity of the single-view setting. The previous state-of-the-art, Decaf, employs a global fitting optimization guided by contact and deformation estimation networks trained on studio-collected data with 3D annotations. However, Decaf suffers from a time-consuming optimization process and limited generalization capability due to its reliance on 3D annotations of hand-face interaction data. To address these issues, we present DICE, the first end-to-end method for Deformation-aware hand-face Interaction reCovEry from a single image. DICE estimates the poses of hands and faces, contacts, and deformations simultaneously using a Transformer-based architecture. It features disentangling the regression of local deformation fields and global mesh vertex locations into two network branches, enhancing deformation and contact estimation for precise and robust hand-face mesh recovery. To improve generalizability, we propose a weakly-supervised training approach that augments the training set using in-the-wild images without 3D ground-truth annotations, employing the depths of 2D keypoints estimated by off-the-shelf models and adversarial priors of poses for supervision. Our experiments demonstrate that DICE achieves state-of-the-art performance on a standard benchmark and in-the- wild data in terms of accuracy and physical plausibility. Additionally, our method operates at an interactive rate (20 fps) on an Nvidia 4090 GPU, whereas Decaf requires more than 15 seconds for a single image. The code will be available at: https://github.com/Qingxuan-Wu/DICE.
@inproceedings{Wu2025DICE, title = {DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single Image}, author = {Wu, Qingxuan and Dou, Zhiyang and Xu, Sirui and Shimada, Soshi and Wang, Chen and Yu, Zhengming and Liu, Yuan and Lin, Cheng and Cao, Zeyu and Komura, Taku and Golyanik, Vladislav and Theobalt, Christian and Wang, Wenping and Liu, Lingjie}, booktitle = {ICLR}, year = {2025}, } -
 InterDreamer: Zero-Shot Text to 3D Dynamic Human-Object InteractionNeurIPS 2024
InterDreamer: Zero-Shot Text to 3D Dynamic Human-Object InteractionNeurIPS 2024Text-conditioned human motion generation has experienced significant advancements with diffusion models trained on extensive motion capture data and corresponding textual annotations. However, extending such success to 3D dynamic human-object interaction (HOI) generation faces notable challenges, primarily due to the lack of large-scale interaction data and comprehensive descriptions that align with these interactions. This paper takes the initiative and showcases the potential of generating human-object interactions without direct training on text-interaction pair data. Our key insight in achieving this is that interaction semantics and dynamics can be decoupled. Being unable to learn interaction semantics through supervised training, we instead leverage pre-trained large models, synergizing knowledge from a large language model and a text-to-motion model. While such knowledge offers high-level control over interaction semantics, it cannot grasp the intricacies of low-level interaction dynamics. To overcome this issue, we further introduce a world model designed to comprehend simple physics, modeling how human actions influence object motion. By integrating these components, our novel framework, InterDreamer, is able to generate text-aligned 3D HOI sequences that go beyond existing mocap data without relying on limited pair data. We apply InterDreamer to the BEHAVE, OMOMO, and CHAIRS datasets, and our comprehensive experimental analysis demonstrates its capability to generate realistic and coherent interaction sequences that seamlessly align with the text directives.
@inproceedings{xu2024interdreamer, title = {InterDreamer: Zero-Shot Text to 3D Dynamic Human-Object Interaction}, author = {Xu, Sirui and Wang, Ziyin and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {NeurIPS}, year = {2024}, } -
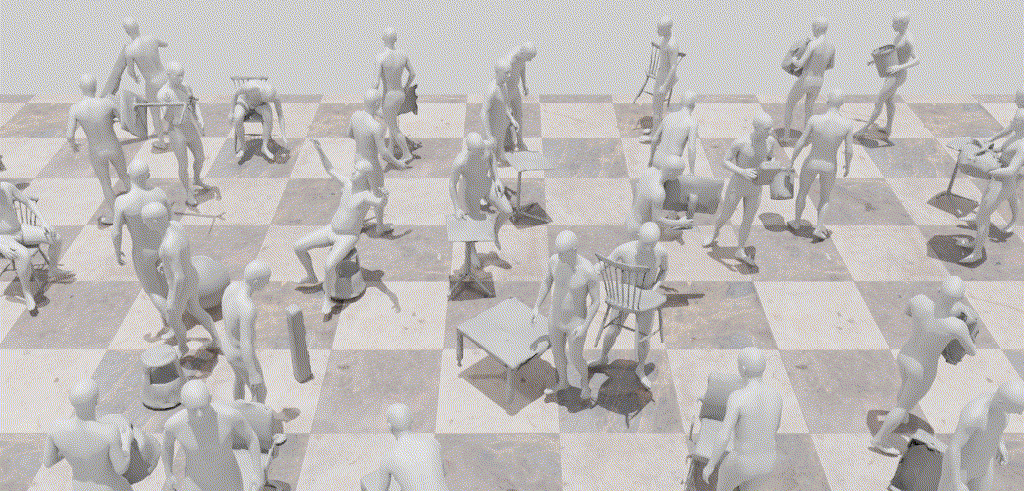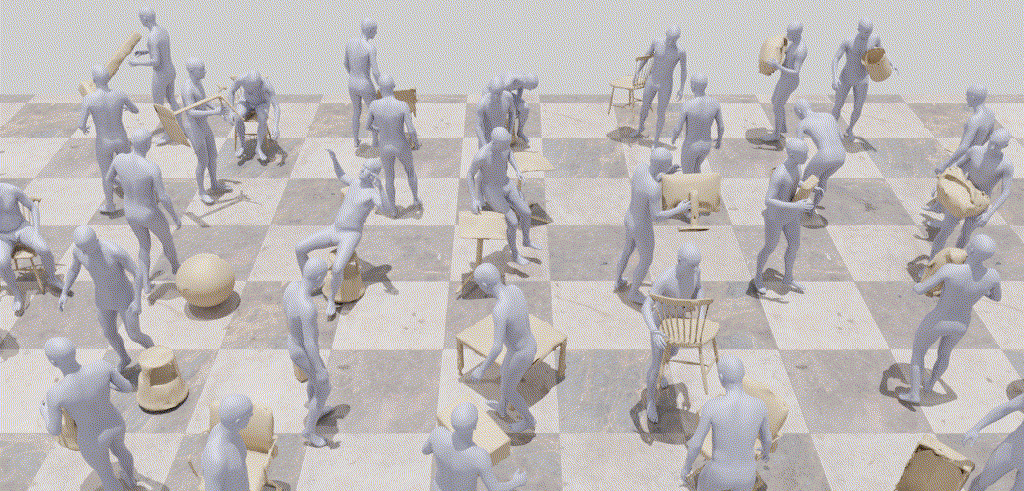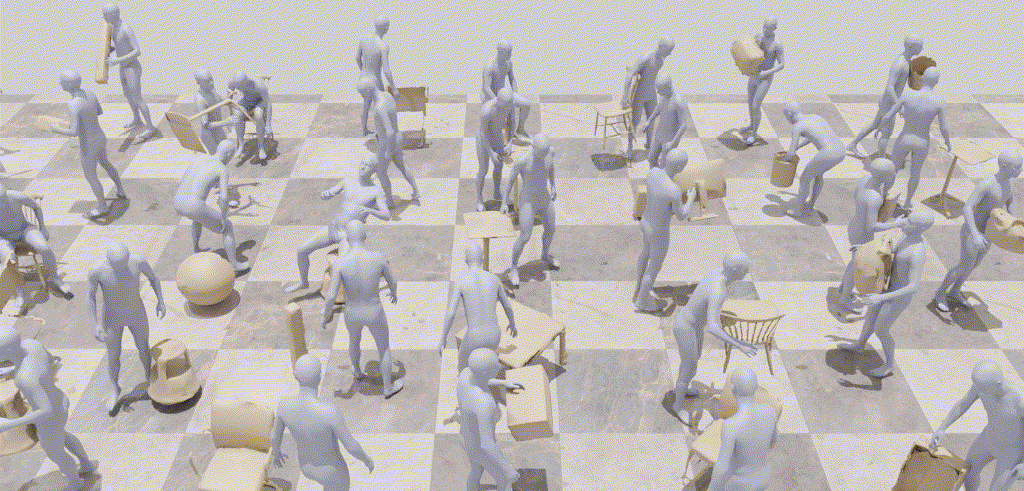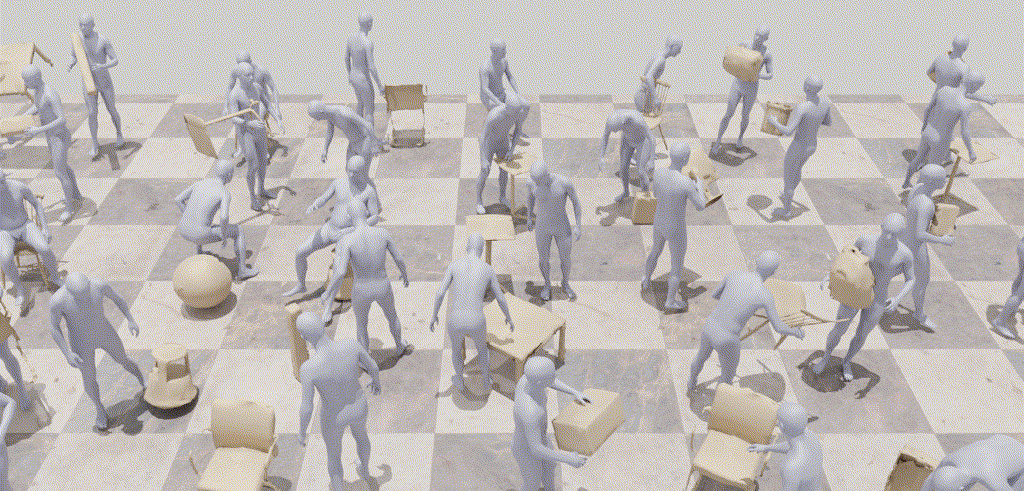 InterDiff: Generating 3D Human-Object Interactions with Physics-Informed DiffusionICCV 2023
InterDiff: Generating 3D Human-Object Interactions with Physics-Informed DiffusionICCV 2023This paper addresses a novel task of anticipating 3D human-object interactions (HOIs). Most existing research on HOI synthesis lacks comprehensive whole-body interactions with dynamic objects, e.g., often limited to manipulating small or static objects. Our task is significantly more challenging, as it requires modeling dynamic objects with various shapes, capturing whole-body motion, and ensuring physically valid interactions. To this end, we propose InterDiff, a framework comprising two key steps: (i) interaction diffusion, where we leverage a diffusion model to encode the distribution of future human-object interactions; (ii) interaction correction, where we introduce a physics-informed predictor to correct denoised HOIs in a diffusion step. Our key insight is to inject prior knowledge that the interactions under reference with respect to contact points follow a simple pattern and are easily predictable. Experiments on multiple human-object interaction datasets demonstrate the effectiveness of our method for this task, capable of producing realistic, vivid, and remarkably long-term 3D HOI predictions.
@inproceedings{xu2023interdiff, title = {InterDiff: Generating 3D Human-Object Interactions with Physics-Informed Diffusion}, author = {Xu, Sirui and Li, Zhengyuan and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {ICCV}, year = {2023}, } - 🏆 Spotlight
 Stochastic Multi-Person 3D Motion ForecastingSirui Xu, Yu-Xiong Wang, and Liang-Yan GuiICLR 2023
Stochastic Multi-Person 3D Motion ForecastingSirui Xu, Yu-Xiong Wang, and Liang-Yan GuiICLR 2023This paper aims to deal with the ignored real-world complexity in prior work on human motion forecasting, emphasizing the social properties of multi-person motion, the diversity of motion and social interaction, and the complexity of articulated motion. To this end, we introduce a novel task of stochastic multi- person 3D motion forecasting. We propose a dual-level generative modeling framework that separately models independent individual movements at the local level and social interactions at the global level. Notably, this dual-level modeling mechanism can be achieved within a shared generative model, through introducing learnable latent codes that represent intents of future movement and switching the codes’ modes of operation at different levels. Our framework is general, and we instantiate it with various multi-person forecasting models. Extensive experiments on CMU-Mocap, MuPoTS-3D, and SoMoF benchmarks show that our approach produces diverse and accurate multi-person predictions, significantly outperforming the state of the art.
@inproceedings{xu2023stochastic, title = {Stochastic Multi-Person 3D Motion Forecasting}, author = {Xu, Sirui and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {ICLR}, year = {2023}, } - 🏆 Oral
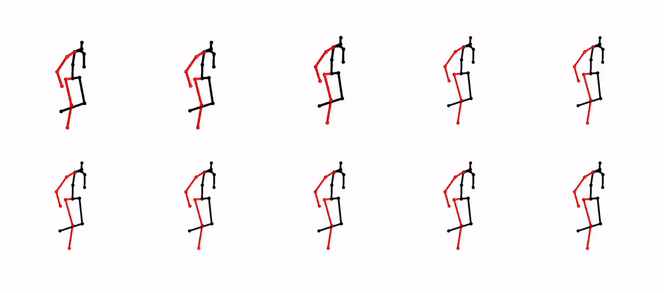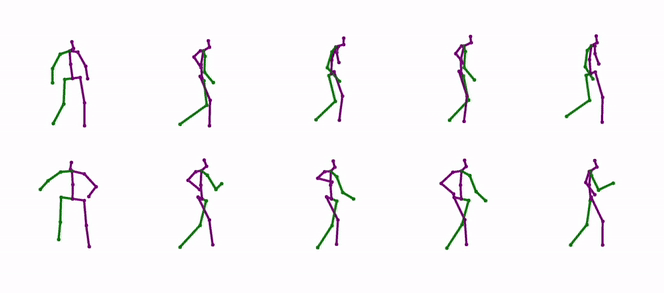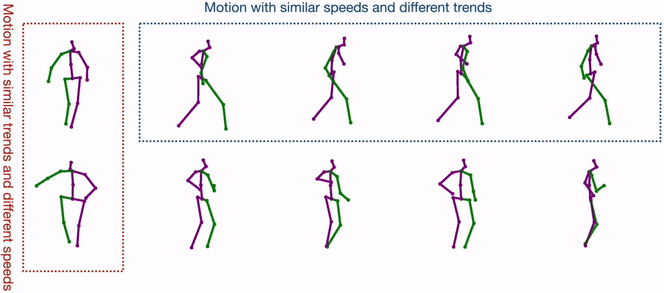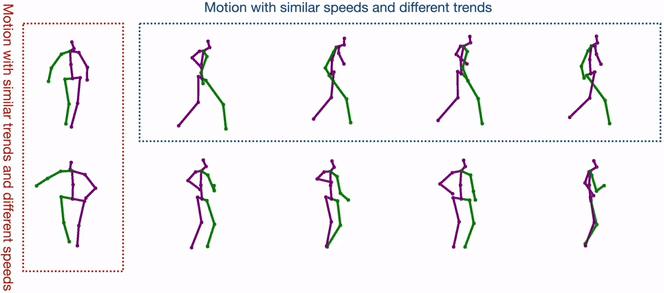 Diverse Human Motion Prediction Guided by Multi-Level Spatial-Temporal AnchorsSirui Xu, Yu-Xiong Wang, and Liang-Yan GuiECCV 2022
Diverse Human Motion Prediction Guided by Multi-Level Spatial-Temporal AnchorsSirui Xu, Yu-Xiong Wang, and Liang-Yan GuiECCV 2022Predicting diverse human motions given a sequence of historical poses has received increasing attention. Despite rapid progress, existing work captures the multi-modal nature of human motions primarily through likelihood-based sampling, where the mode collapse has been widely observed. In this paper, we propose a simple yet effective approach that disentangles randomly sampled codes with a deterministic learnable component named anchors to promote sample precision and diversity. Anchors are further factorized into spatial anchors and temporal anchors, which provide attractively interpretable control over spatial-temporal disparity. In principle, our spatial-temporal anchor-based sampling (STARS) can be applied to different motion predictors. Here we propose an interaction-enhanced spatial-temporal graph convolutional network (IE-STGCN) that encodes prior knowledge of human motions (e.g. spatial locality), and incorporate the anchors into it. Extensive experiments demonstrate that our approach outperforms state of the art in both stochastic and deterministic prediction, suggesting it as a unified framework for modeling human motions.
@inproceedings{xu22stars, title = {Diverse Human Motion Prediction Guided by Multi-Level Spatial-Temporal Anchors}, author = {Xu, Sirui and Wang, Yu-Xiong and Gui, Liang-Yan}, booktitle = {ECCV}, year = {2022}, }