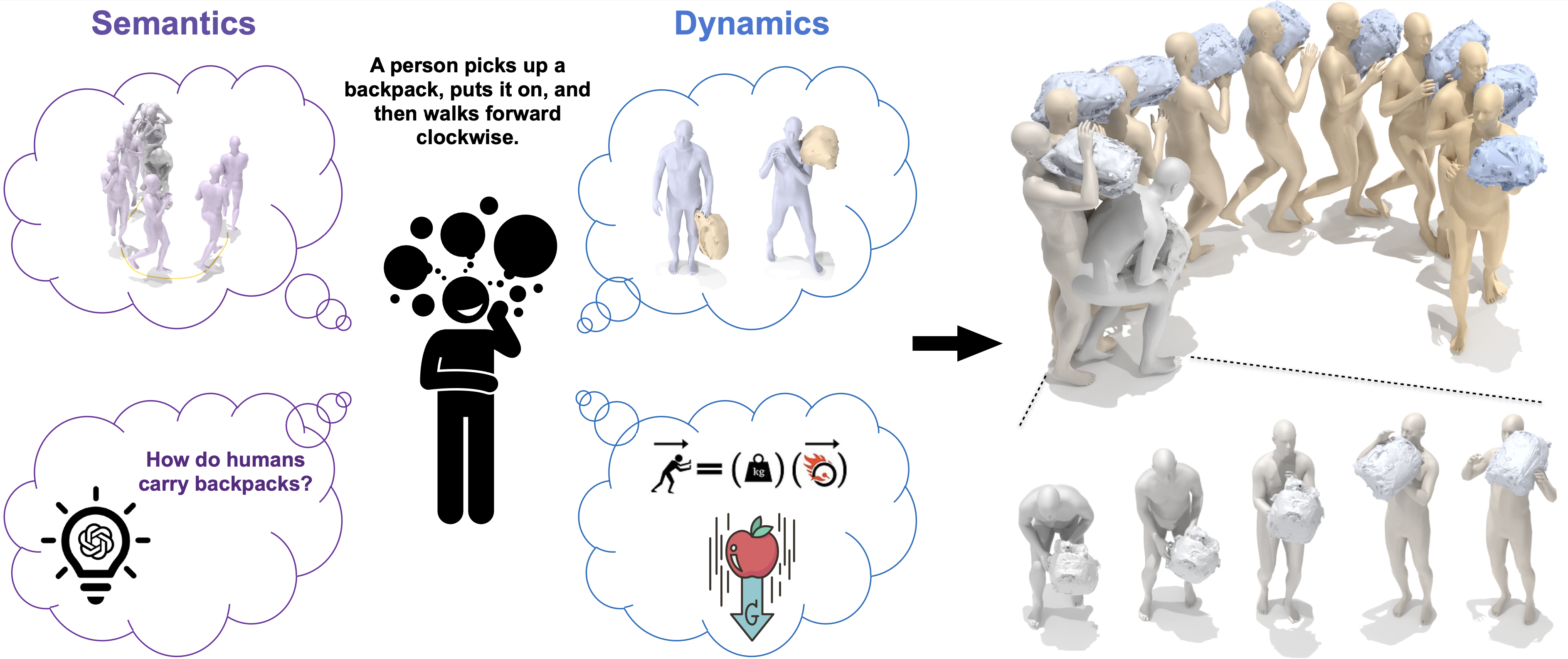
Text-conditioned human motion generation has experienced significant advancements with diffusion models trained on extensive motion capture data and corresponding textual annotations. However, extending such success to 3D dynamic human-object interaction (HOI) generation faces notable challenges, primarily due to the lack of large-scale interaction data and comprehensive descriptions that align with these interactions. This paper takes the initiative and showcases the potential of generating human-object interactions without direct training on text-interaction pair data. Our key insight in achieving this is that interaction semantics and dynamics can be decoupled. Being unable to learn interaction semantics through supervised training, we instead leverage pre-trained large models, synergizing knowledge from a large language model and a text-to-motion model. While such knowledge offers high-level control over interaction semantics, it cannot grasp the intricacies of low-level interaction dynamics. To overcome this issue, we further introduce a world model designed to comprehend simple physics, modeling how human actions influence object motion. By integrating these components, our novel framework, InterDreamer, is able to generate text-aligned 3D HOI sequences in a zero-shot manner. We apply InterDreamer to the BEHAVE and CHAIRS datasets, and our comprehensive experimental analysis demonstrates its capability to generate realistic and coherent interaction sequences that seamlessly align with the text directives.
⚔️ Comparison to Existing Work on Supervised Learning
We evaluate our model on the annotated data available from concurrent work, which is unseen to our zero-shot model, retrieving their generated videos for direct comparison. Remarkably, even without training on these datasets, our method generates high-quality interactions. In addition, our system can accept free-form input from any of their annotations, whereas existing work cannot.
📹 More Visualizations
Contact remains largely unchanged
A person holds a backpack with their left hand and drags it.
A person holds a plastic container with their right hand and moves it in different directions.
A person walks clockwise while holding a small box with left hand.
A person is seated in a chair.
A person holds a small table with their right hand and pulls it backward.
A person picks up a toolbox with their right hand and walks a few steps.
A person stands up from a chair.
More challenging cases: Contact is dynamically-changing
A person moves a long box in their left hand downward, to the right and then to the left.
A person holds a medium box up with their right hand, lowers their right arm, and pulls the box with left hand towards them.
A person throws a yoga ball towards the ground.
A person transfers a plastic container from their left hand to their right hand.
A person places a large box on the right side, then moves it to the left side.
📖 Method Overview
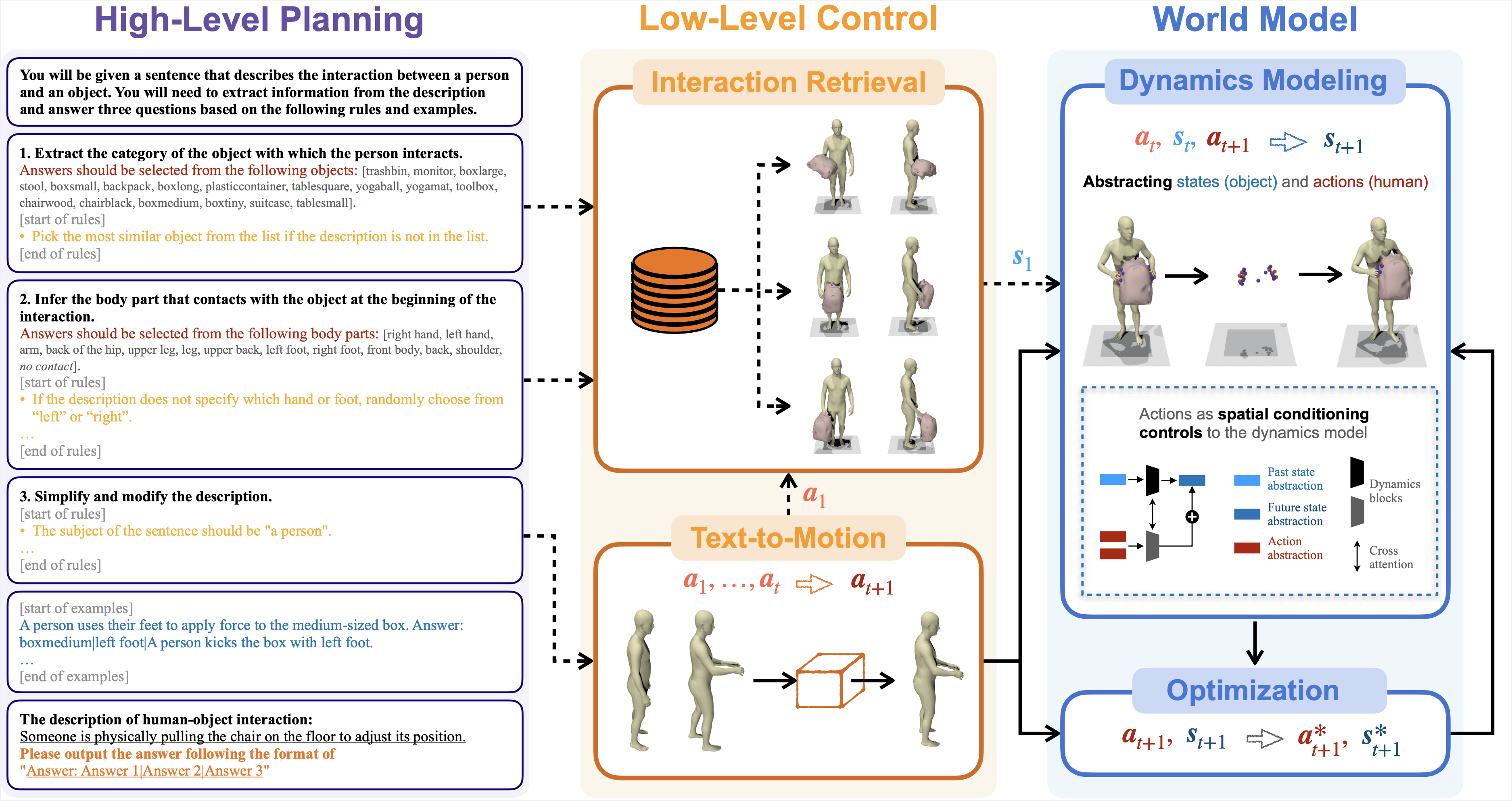
InterDreamer can generate vivid 3D human-object interaction sequences guided by textual descriptions. Its zero-shot ability is achieved by integrating semantics and dynamics knowledge from large-scale text-motion data, a large language model (LLM), 3D human-object interaction database, and interaction prior.
- (i) High-level planning analyzes the description using LLMs and provides guidance to the low-level control.
- (ii) Low-level control includes a text-to-motion model that translates text into human actions, and an interaction retrieval model for extracting the object's initial pose as the first state.
- (iii) World model executes the actions and outputs the next state through dynamics modeling. An optimization process is coupled with the dynamics model, projecting the state and action onto valid counterparts.
Failure Cases
A person turns a plastic container to the right with both hands and sits down.
Inconsistency of interaction with textual instructions
A person half-squats and pushes and pulls a black chair with their right hand.
Inconsistency of human actions with textual instructions
A person supports a toolbox with their left hand.
Low quality of human motion (sudden changes)
BibTex
@article{xu2024interdreamer,
title={InterDreamer: Zero-Shot Text to 3D Dynamic Human-Object Interaction},
author={Xu, Sirui and Wang, Ziyin and Wang, Yu-Xiong and Gui, Liang-Yan},
journal={arXiv preprint arXiv:2403.19652},
year={2024},
}